

This release includes a slight optimization in how we handle requests that are already processing where visitors of Magento shops click away when the server is under high load.
Smart request handling on Hypernode
On Hypernode servers we do various things to filter out unnecessary work. Under normal load these mechanism aren’t really noticeable but once the web server is starting to hit its limit these optimizations can really make a difference.
One of the things we do is disregard requests of which we know nobody is waiting on the other end. This will prevent requests with still active clients from waiting unnecessarily. With this optimization a snowballing effect can be avoided where those still waiting active requests become stale as well because the visitor of a webshop gets tired of waiting or the client times out.
In a worst case scenario such a cascading effect could cause the web server to process no meaningful work at all while the performance of the webshop grinds to a halt, blocking new incoming requests with still active clients ad infinitum.
Example on how requests are handled by a web server
For example, if you hold F5 (refresh) when you are on a website your web-browser will send many requests to the web server*. The requests are queued on the web-server in FIFO order. The first requests that come in are the first requests that are processed, while in this scenario the only important request is the last one because that is what the user is looking at in the browser. There is nothing waiting for the response for any of the earlier requests.
This simplified scenario also exists on a larger scale in a model with many visitors. When the site becomes slow or unresponsive people start refreshing or clicking around causing a counter-productive effect on the web server if the cause of the slowness is an overloaded server.
How to avoid an overloaded web server
To combat this situation we employ two mechanisms. The first one is that we do not pass any requests from the NGINX requests queue to PHP-FPM if we see that the client is already gone coming in. The second is to terminate requests that are already processing but become GONE during their lifetime and can be aborted safely.
We have implemented the first strategy using the php-hypernode PHP extension. This is a PHP module that we have written that intercepts the PHP-FPM handler from NGINX and inspects the connection socket to see if it is in a TCP_CLOSE_WAIT state. If so, we can conclude that the client is already gone and we don’t have to pass it to PHP for processing. This module is open-source and you can check it out on github here.
Terminating running requests that become GONE on Hypernode
The change in this release is about the second strategy: terminating running requests that become GONE during their lifetime. Once the requests start processing there is still someone waiting on the other end, but if the processing takes too long the visitor might click away. At that point the request becomes GONE as well.
We perform the detection by using hypernode-fpm-status to check the PHP-FPM workers for their status periodically. If the PHP-FPM workers are saturated and there are requests marked with a GONE status (we check for TCP_CLOSE_WAIT here as well) that we can safely terminate we kill said requests to make room new incoming requests and start a loop that starts checking for GONE requests really quickly until the server quiets down.
Under normal circumstances it does not make sense to check the FPM status more often than once per minute because it is a relatively heavy operation. But if a full queue and GONE requests are detected it indicates that the server might be overloaded (or is about to be) and is spending a lot of computing power handling these stale requests.
In that case it makes sense to start spending computing power to check for these requests rapidly in order to fight the cascading effect to prevent PHP-FPM workers to be wasted on processing pages nobody is waiting for on the other end, which in turn might have caused more repeated requests because users got tired of waiting and refreshed or clicked away.
In this release we increase the time between checking for GONE requests in the quick-checking mode. Currently we check in a very short interval, but we have noticed that under sustained high load with many workers polling the FPM workers this often is not as effective in some cases as checking it using a longer interval. For example, see this screenshot:
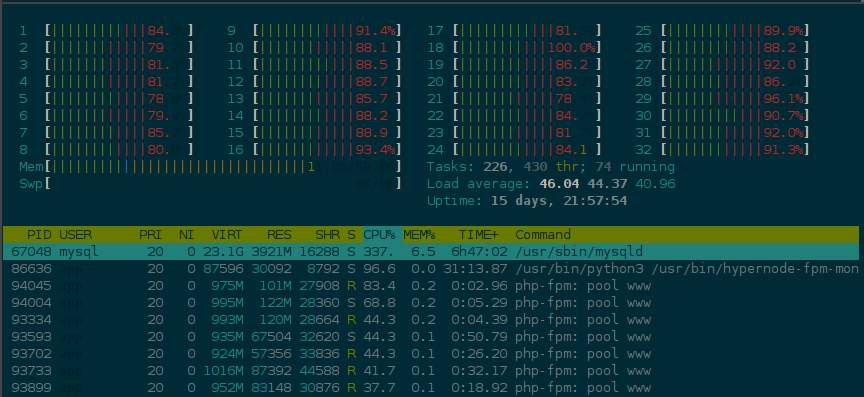
In this scenario of prolonged and sustained high load with many PHP-FPM workers the amount of resources expended to save wasted resources becomes disproportionate because of the repeated polling of all running processes. In this release we tweak the wait for checking GONE requests in the quick-checking scenario to once every 15 seconds to limit the impact the detection process itself with the goal of slightly improving throughput under high load on large Hypernodes.
* Note that this does not actually work this way on a Hypernode because there is a per IP rate-limit. I mention this example to demonstrate the situation in the small, but it really only occurs on a larger scale with many visitors.