

Upgrades and downgrades between the Professional 2XL, 3XL, 4XL and 5XL plans (Combell OpenStack) and Excellence 2XL, 3XL, 4XL and 5XL plans (Amazon) will now keep the same cloud volume during migrations instead of copying the filesystem from the old instance to the new one like before. This speeds up the data transfer step in migrations from multiple minutes (variable depending on the amount of data and rate of change on disk) to less than one minute for these specific node sizes.
Since its inception the vision for Hypernode has been to build a cloud-agnostic and multi-cloud platform. We purposely only use cloud functionality that can be re-implemented on different clouds. This gives us the benefit of being able to always seek out the best and the latest in cloud technology without having to worry about vendor lock-in so we can improve our offering if it makes sense to do so.
But over time we have spotted certain patterns in cloud semantics that have given us the opportunity to implement certain ‘short-cuts’ in our automation depending on the environment in which the operation takes place. We have generic mechanisms in place to handle new node creations, upgrades and removals between and across different cloud providers.
To perform these state transitions and keep them compatible we must conform to the lowest common denominator. Unfortunately that comes at the cost of not always being able to take the most efficient route. Lately we have been investigating possibilities for improvements to be made in order to streamline certain processes when possible if the environment allows it.
An earlier example of this is this update from January where we short-circuited our node scheduler to not perform a migration if the destined instance was of the exact same size and flavor as the original machine. The advantage of that manifested itself in being able to upgrade and downgrade between development versions of the same plan without performing an actual migration.
Over the past couple of weeks we have been developing an optimization where we utilize the circumstances of a Hypernode to determine if we can take a new kind of short-cut.
The generic migration process
When the product of a Hypernode is changed an automated process is executed which we call the ‘xgrade’ (for up or downgrade). This process consists of provisioning a completely new Hypernode of the specified size, copying the data from the old Hypernode to the new one and updating the DNS.
The actual process is a bit more convoluted than that, but conceptually that is what happens. To perform the data synchronization we first perform a pre-sync where we copy the data to the new node while the old node continues functioning. Up until this point nothing has changed from the perspective of the original machine.
When the complete dataset has been synced to the new instance, we stop the services on the old system to prevent new orders from coming in and then perform a second quick synchronization to make sure that everything that has changed since the initial synchronization is transfered as well. After that point the DNS is updated, the services are started on the new machine and the migration has been completed.
This process is generic in the sense that it works between all sorts of cloud-providers. It does not matter if you are performing a migration between two DigitalOcean nodes, an Amazon node to a DigitalOcean node or anywhere else. As long as there is SSH and we can perform the relevant cloud API calls this method will be compatible.
DigitalOcean
|
.===========. | .===========.
| hypernode |>-rsync->| hypernode |
'===========' '==========='The specialized migration process
While the generic migration process is a great boon for connecting Hypernode to new clouds quickly so we can evaluate new platforms, it is not always the most efficient. For example, in modern public clouds there is often the notion of ‘external volumes’ where the primary data storage is not coupled to the instance.
For example, at Amazon a Hypernode actually exists out of an EC2 instance combined with an Elastic Block Store volume. This storage volume is an external resource that is associated with the instance and can conceptually be abstracted out as a StorageVolume as available on other clouds as well such as OpenStack.
Currently at Amazon we use the generic migration process which looks like something like this:
Amazon
|
.==========. | .==========.
| instance |>-rsync->| instance |
'==========' | '=========='
|| | ||
.========. | .========.
| volume | | | volume |
'========' | '========'
As you can see, the conventional rsync is used after a new instance is created with a new empty volume attached. Once the migration has been completed the old instance and volume are discarded while the new larger (or smaller) node lives on.
Especially because most Amazon Hypernodes are of the larger variation this can start inciting some less than optimal behavior. If the webshop is doing a lot of IOPS or is processing a large amount of data the final sync could take a while. Even the time it takes to check which files have changed during the second synchronization can start stacking up if there are many many small files on the system.
To improve on this process we have implemented a new type of migration, the ‘volume swap migration’, for when the volume will remain the same between an upgrade or downgrade. This currently means that only the Excellence 2XL, 3XL, 4XL and 5XL Hypernodes are eligible to utilize this new method. These plans are the three largest Hypernode products at the time of writing and they all have the exact same disk type.
That last part is significant because we can not start shuffling just any types of disks around. The difference in denomination would cause an unmanageable drift in configuration. To prevent this we declaratively detect if the product that is being migrated to is at the same cloud provider in the same region and has the same size storage volume, and if so the new migration method will be used.
Swapping the volumes on live instances
It works like this: like before we provision a new larger of smaller Hypernode, but instead of copying the data from the old machine over the network we stop the services on the old node and detach the volume from the old instance using the API and reattach and mount it on the new machine before updating the DNS. This is effectively the same as yanking out the disk from one computer and putting it in a bigger one.
Amazon
|
.==========. | .==========.
| instance | | | instance |
'==========' | '=========='
|| |
.========. |
| volume |
'========' Amazon
|
.==========. | .==========.
| instance | | | instance |
'==========' | '=========='
detach |
.========. |
| volume | --->
'========' Amazon
|
.==========. | .==========.
| instance | | | instance |
'==========' | '=========='
| attach
| .========.
| | volume |
| '========' Amazon
|
.==========. | .==========.
| instance | | | instance |
'==========' | '=========='
| ||
| .========.
| | volume |
| '========'As you can imagine, the time gained by this can be enormous, especially considering worst case scenarios where during a traditional migration a lot of files have the potential to change on disk dragging out the downtime during the second synchronization.
We have timed the volume swap to complete in under one minute. This time can vary depending on a multitude of factors like the time it takes to gracefully stop the services on the original machine (and re-start them on the new machine), and other out of the ordinary events like cloud anomalies where the detaching or attaching of volumes takes longer than the norm.
Note that web availability is still bound by the TTL of the DNS change. But as soon as the services of the new node have been started after mounting the volume, processing can continue. Overall this should be a great improvement in usability and the benefits will definitely be noticeable if you ever need to upgrade between these specific plans in a pinch.
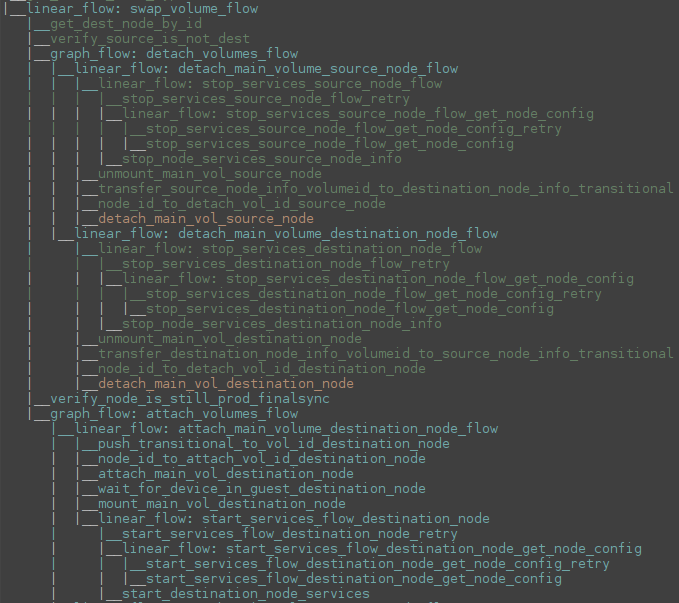
As an additional illustration, this screenshot is a visualization of the execution graph of the volume swapping process running on our distributed job processing system. Every step in this graph has a corresponding revert method where we can execute the reverse action to minimize downtime in case anything unexpected happens and we need to abort or retry.
We will be deploying this new migration method to the Hypernode production systems over the course of the coming week.